


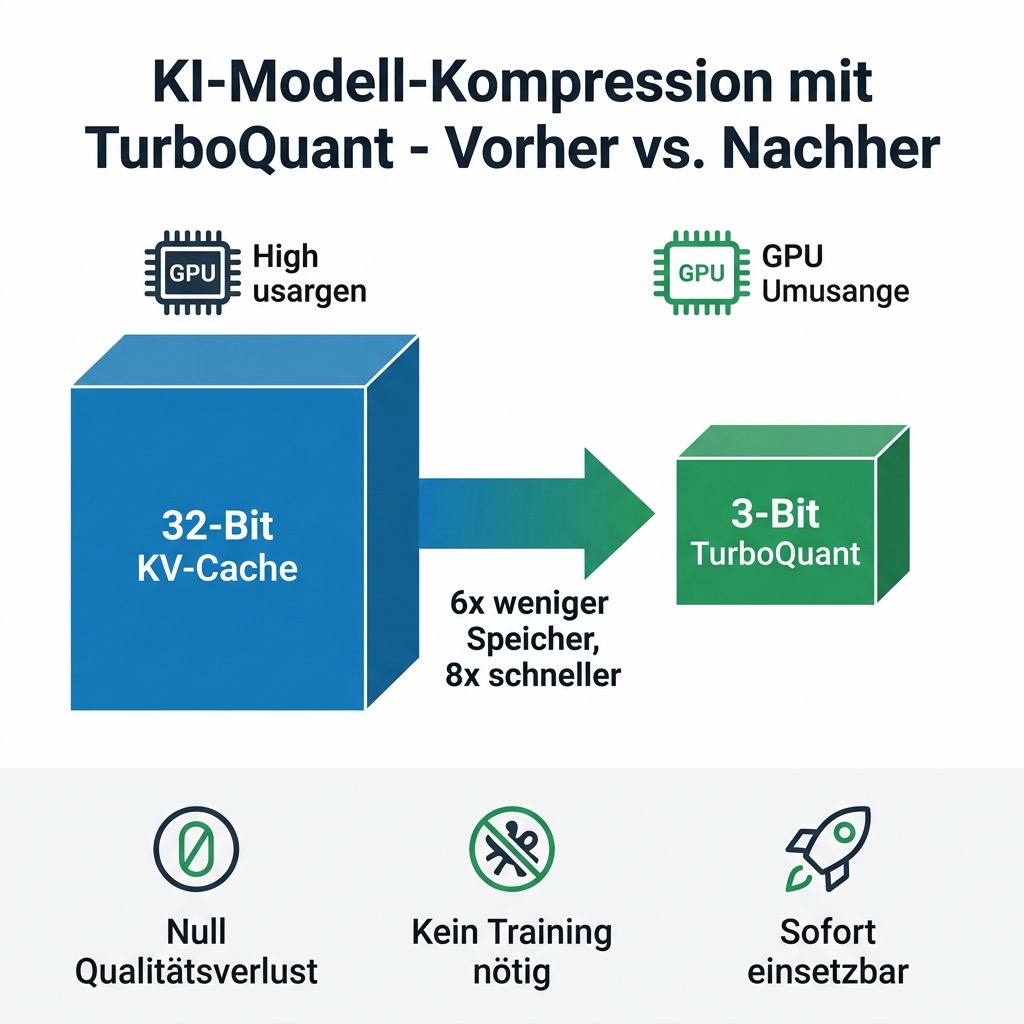
6x weniger Speicher, 8x schneller – und null Kompromisse bei der Qualität?
Klingt nach Marketing-Versprechen. Ist es aber nicht. Google Research hat Ende März 2026 TurboQuant vorgestellt – einen Kompressionsalgorithmus, der den Speicherverbrauch von KI-Modellen um den Faktor 6 reduziert und gleichzeitig die Verarbeitungsgeschwindigkeit auf das Achtfache steigert. Und das ohne jeglichen Qualitätsverlust.
Für IT-Dienstleister, die ihre Kunden bei der Einführung von KI-Lösungen begleiten, ist das mehr als eine technische Fußnote. Es ist ein Signal, dass sich die Ökonomie der KI-Inferenz gerade fundamental verschiebt.
Das Problem: Der KV-Cache als Flaschenhals der KI-Inferenz
Jedes Mal, wenn ein großes Sprachmodell (LLM) einen Text generiert, speichert es sogenannte Key-Value-Paare in einem Cache – dem KV-Cache. Dieser Zwischenspeicher hilft dem Modell, bereits verarbeitete Informationen nicht erneut berechnen zu müssen. Das Problem: Der KV-Cache wächst linear mit der Länge des Kontexts.
Bei einem 70-Milliarden-Parameter-Modell mit 128.000 Token Kontext belegt allein der KV-Cache rund 40 Gigabyte an GPU-Speicher. Bei tausend gleichzeitigen Nutzern berechnet ein Cluster dieselben Daten immer wieder neu. Studien zeigen, dass der KV-Cache bei langen Texten bis zu 70 Prozent des gesamten GPU-Speichers beanspruchen kann.
Bisherige Kompressionsverfahren – sogenannte Vektorquantisierung – konnten diesen Speicher zwar reduzieren, brachten aber einen eigenen Overhead mit: Für jeden Datenblock mussten zusätzliche Quantisierungskonstanten in voller Präzision gespeichert werden. Das fraß 1 bis 2 Bit pro Zahl wieder auf und machte einen Teil der Einsparung zunichte.
TurboQuant: Drei Algorithmen, ein Durchbruch
TurboQuant löst dieses Problem durch eine Kombination aus drei mathematisch fundierten Algorithmen, die Google Research in drei separaten Papers veröffentlicht hat:
- PolarQuant: Wandelt Vektordaten von kartesischen in Polarkoordinaten um. Statt X-, Y-, Z-Positionen speichert es Radius und Winkel. Weil die Winkelverteilung vorhersagbar ist, entfällt die aufwändige Datennormalisierung. Ergebnis: kein Speicher-Overhead.
- QJL (Quantized Johnson-Lindenstrauss): Reduziert hochdimensionale Daten auf ein einziges Vorzeichen-Bit (+1 oder -1) pro Wert – bei null Speicher-Overhead. Ein spezieller Schätzer gleicht die Genauigkeit zwischen der hochpräzisen Anfrage und den vereinfachten Daten aus.
- TurboQuant selbst: Kombiniert PolarQuant für die Hauptkompression mit QJL als mathematischem Fehlerkorrekturschritt. PolarQuant übernimmt den Großteil der Kompression, QJL eliminiert mit nur 1 Bit den verbleibenden Restfehler.
Das Ergebnis: TurboQuant komprimiert den KV-Cache auf 3 Bit pro Wert – ohne Training, ohne Feintuning und ohne Qualitätseinbußen. Auf NVIDIA H100-GPUs erreicht die 4-Bit-Variante eine bis zu achtfache Beschleunigung gegenüber unkomprimierten 32-Bit-Keys.
Die Benchmarks sprechen eine klare Sprache
Google hat TurboQuant auf mehreren etablierten Long-Context-Benchmarks getestet, darunter LongBench, Needle-In-A-Haystack, ZeroSCROLLS und RULER. Eingesetzt wurden Open-Source-Modelle wie Gemma und Mistral.
Die Ergebnisse: TurboQuant erreicht bei allen Needle-in-a-Haystack-Aufgaben – also Tests, bei denen ein Modell eine einzelne Information in riesigen Textmengen finden muss – perfekte Ergebnisse. Gleichzeitig reduziert es den KV-Speicher um mindestens den Faktor 6. Auch PolarQuant allein ist nahezu verlustfrei.
Bei der Vektorsuche übertrifft TurboQuant etablierte Verfahren wie PQ und RabbiQ bei der Recall-Rate – und das ohne die aufwändigen, datensatzspezifischen Codebooks, die diese Methoden benötigen.
„TurboQuant zeigt, dass sich die Grenzen der KI-Inferenz nicht nur durch größere GPUs verschieben lassen, sondern durch intelligentere Algorithmen. Für IT-Dienstleister bedeutet das: Die Hardware-Kosten für KI-Projekte könnten in den nächsten Monaten deutlich sinken – wer das versteht, kann seinen Kunden heute schon bessere Angebote machen.“, so Ingo Lücker, Gründer der KI LEAGUE.
Warum das für die KI-Ökonomie ein Wendepunkt ist
Die Kosten für KI-Inferenz sind in den vergangenen drei Jahren um den Faktor 1.000 gesunken. Anfang 2026 kostet die Leistung auf GPT-4-Niveau etwa 0,40 US-Dollar pro Million Token – gegenüber 20 US-Dollar Ende 2022. Inferenz macht mittlerweile rund zwei Drittel aller KI-Rechenleistung aus, Tendenz steigend.
Gleichzeitig explodieren die Kosten für GPU-Infrastruktur in der Cloud: Zwischen 2 und 32 Euro pro Stunde kostet eine GPU-Instanz bei den großen Cloud-Anbietern – das 10- bis 30-Fache einer vergleichbaren CPU-Stunde. Ein einzelner NVIDIA DGX H100-Server schlägt mit rund 300.000 Euro zu Buche.
Algorithmen wie TurboQuant setzen genau hier an. Wenn der KV-Cache auf ein Sechstel schrumpft, passen mehr gleichzeitige Nutzer auf dieselbe Hardware. Wenn die Inferenz achtmal schneller läuft, sinken die Kosten pro Token drastisch. Das ist nicht inkrementell – das ist multiplikativ.
Was das für IT-Dienstleister konkret bedeutet
Für Systemhäuser und IT-Dienstleister, die ihre Kunden bei KI-Projekten begleiten, ergeben sich drei konkrete Handlungsfelder:
- KI-Infrastruktur neu kalkulieren: Wenn Kompressionsalgorithmen wie TurboQuant den Speicherbedarf um Faktor 6 senken, verändert das die Hardware-Anforderungen fundamental. Projekte, die bisher Multi-GPU-Setups erforderten, könnten bald auf einer einzigen Karte laufen.
- Edge-KI wird realistischer: Weniger Speicherbedarf und schnellere Inferenz machen es möglich, leistungsfähige KI-Modelle direkt beim Kunden zu betreiben – ohne Cloud-Abhängigkeit. Gerade in regulierten Branchen ist das ein entscheidender Vorteil.
- Wettbewerbsvorteil durch Wissensvorsprung: Wer versteht, wie Quantisierung und Kompression die Kostenstruktur von KI-Projekten verändern, kann seinen Kunden heute schon belastbare TCO-Kalkulationen liefern.
„Die eigentliche Disruption bei der KI passiert nicht bei den Modellen selbst – sie passiert bei der Infrastruktur. Algorithmen wie TurboQuant machen KI billiger, schneller und lokaler einsetzbar. IT-Dienstleister, die das auf dem Schirm haben, werden die ersten sein, die ihren Kunden echte Wertschöpfung liefern.“, so Ingo Lücker, Gründer der KI LEAGUE.
Einordnung: Was jetzt sinnvoll ist – und was nicht
Sinnvoll ist jetzt:
- Die Entwicklung bei KI-Kompression und Quantisierung aktiv verfolgen – TurboQuant wird auf der ICLR 2026 präsentiert und ist Open-Source-fähig getestet.
- Bestehende KI-Infrastrukturplanung hinterfragen: Braucht das nächste Kundenprojekt wirklich die maximale GPU-Konfiguration?
- Kunden proaktiv über sinkende Inferenzkosten informieren – das schafft Vertrauen und positioniert als kompetenter Partner.
Nicht sinnvoll ist:
- Jetzt auf die nächste GPU-Generation warten und Projekte verzögern – die Software-Seite der Optimierung ist bereits da.
- Kompression als Nischenthema abtun – es betrifft jedes KI-Projekt, das in Produktion geht.
- Sich ausschließlich auf API-Preise der Cloud-Anbieter verlassen, ohne die darunterliegende Technologie zu verstehen.
Einladung zum nächsten KI LEAGUE Live Talk
Der Live Talk richtet sich bewusst an IT-Dienstleister und Systemhäuser, die KI einordnen wollen. Die Teilnahme ist kostenlos – der Austausch ausdrücklich erwünscht.
Einladung zur KI LEAGUE
Die KI LEAGUE ist der Ort für IT-Dienstleister, die KI nicht hypen, sondern verstehen wollen. Als Plattform für Einordnung, Austausch und kritische Diskussion – jenseits von Buzzwords und Produktversprechen.
Jetzt informieren und dabei sein



